The process of diving into the textual data from the Works’ Progress Administration Slave Narratives has been a fascinating one, and it highlights the ways in which tools such as Voyant, Carto and Palladio can reveals nuances in a text that are not readily apparent using one tool alone. While all three applications rely on visualization to help the user understand the text on a deeper level, they do so in different ways.
The initial analysis of the corpus of the interviews in Voyant allowed me to discover what words (massa, house, mammy, white) come up frequently in the documents after filtering for extraneous text. Voyant also helps me to make serendipitous discoveries based on information contained in the summary view. Perhaps more than any of the other tools, Voyant is able to do many different tasks in order to help the user to understand what the texts themselves reveal.
However, things are not always as they seem, and careful analysis in Voyant makes it evident that the texts may not be as straight forward as they seem. The READER view hints that although these are the Alabama narratives, they may contain information about enslavement in states outside of Alabama such as Georgia. However, Voyant is not equipped to flesh out these nuances in an efficient manner.
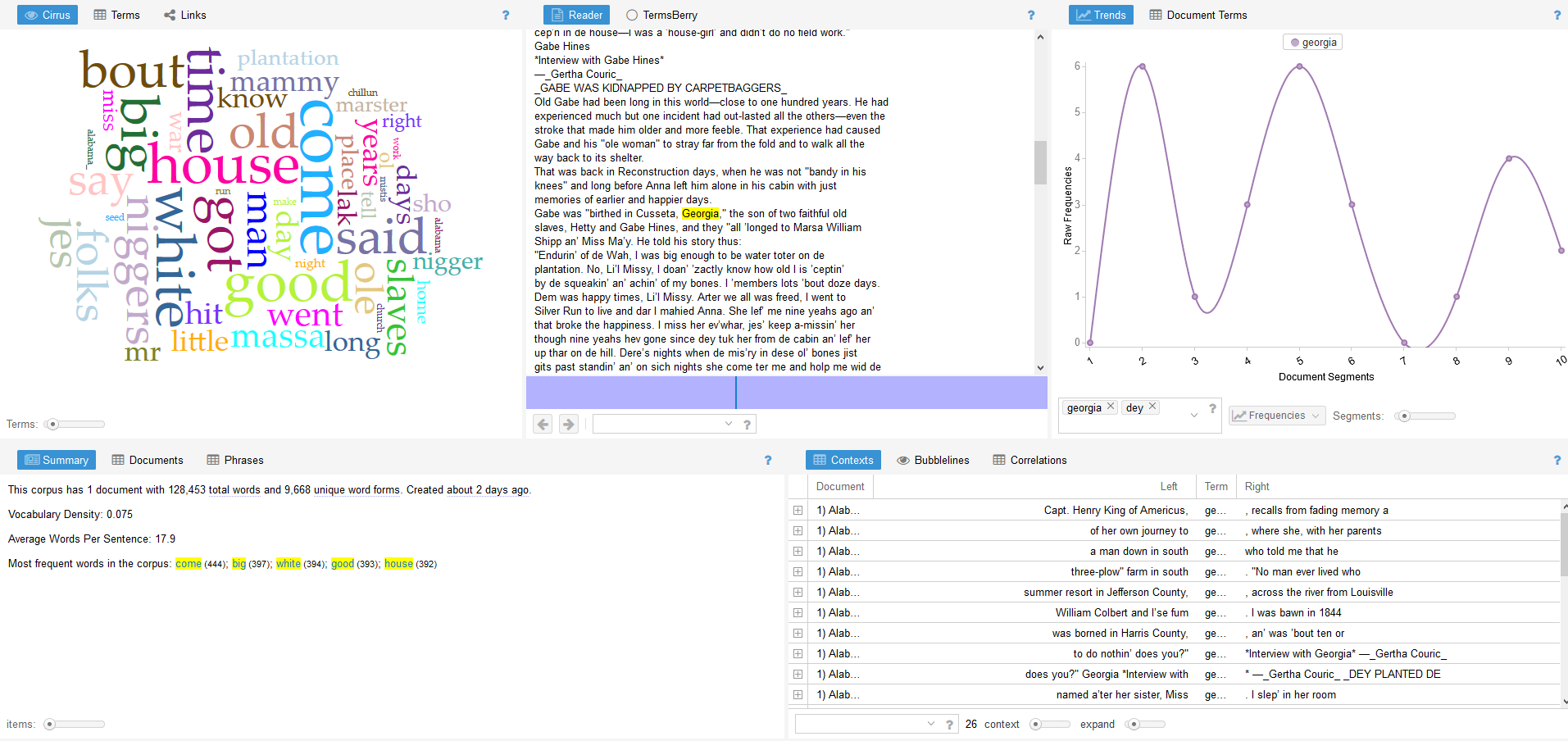
Voyant READER view shows slave experience in Georgia within Alabama Narrative document
Conversely, Carto is a powerful tool in fleshing out these differences. By mapping different aspects of the metadata of each individual record, it is easy to see that a sizable portion of the Alabama document recounts the experience of enslaved persons outside of Alabama. If one were to load the metadata of the entire corpus into Carto, it would be possible to map where the accounts of persons actually enslaved in Alabama occur throughout the corpus of the Slave Narratives regardless of the state documents in which they appear. In this way, researchers could visually identify the geographic locations of these interviews. Theoretically, they could go back and manually create a revised set of Alabama documents to run through Voyant to get a more accurate understanding of the experience of those actually enslaved in Alabama. However, based on the data sets available, Carto is not able to map the names of the actual persons interviewed, only their location.

Carto Map showing disparity between the location of enslavement and the location of interview
Finally, Palladio allows researchers to refine the data on a more precise level and also allows researchers to ask different questions of the data. Building on the ways in which Carto has confirmed initial suspicions about disparities between interview location and enslavement highlighted by Voyant, Palladio is able to use the metadata to filter for persons actually enslaved in Alabama in a much more efficient manner than is possible in Carto. Theoretically, the entire corpus of the Slave Narratives could be loaded into Palladio allowing users more easily create a new data set of those enslaved in Alabama regardless of interview location.
Palladio also allows users to visualize how the interviews can be analyzed as individual units instead of at the document level available in Voyant. This allows users to understand who was being interviewed by gender, job status, topic, etc. as well as how interviews were collected by individual interviewers. This information would be helpful to researchers in understanding the potential for gender bias in how the interviews were collected.
Finally, Palladio allows the researcher to look at interviews based on topics listed in the metadata. And, this provides an interesting contrast to the original query in Voyant. The initial visualization in Voyant helps the user to understand what the body of the text reveals about word frequency. However, very few of these words appear in the topics included in the metadata. In fact one of the only words to pop out in both visualizations, mammy, seems to be a word that is somewhat isolated in the larger context of the Alabama slave experience. Though many of the words in the Voyant word cloud are related to the topics expressed in Palladio, few are exact. Thus, the Palladio visualization helps the researcher to understand how the choices made by the creators of the metadata influence how the larger body of the text set may be interpreted.
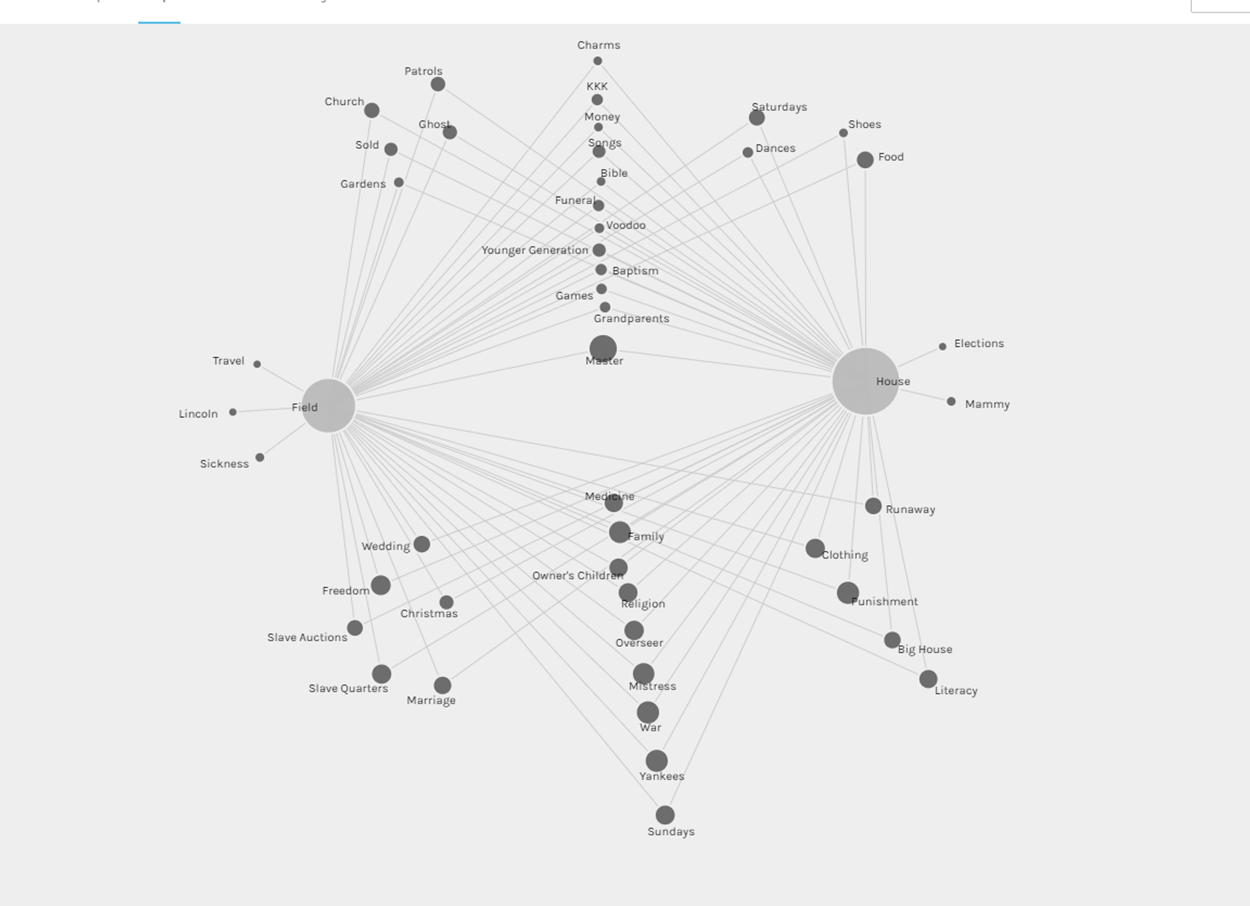
Palladio visualization showing topic map based on type of work among those persons enslaved in Alabama.
Visualization tools are helpful in understanding a body of text in order to formulate better questions about the text set; however, they rarely express clear cut answers about a text in the ways that mathematical graphs visually express numerical sets.